
CQRS porządkuje jeden z najczęstszych konfliktów w aplikacjach biznesowych: zapis danych i ich odczyt rzadko mają te same wymagania. Ja patrzę na ten wzorzec jak na sposób na lepsze rozdzielenie odpowiedzialności, a nie modny skrót z architektury rozproszonej. Poniżej wyjaśniam, czym jest Command Query Responsibility Segregation, jak działa w praktyce, kiedy daje realną przewagę i gdzie łatwo przesadzić.
Najkrócej: CQRS rozdziela zapis i odczyt, ale robi to z konkretnym kosztem
- Wzorzec oddziela komendy, które zmieniają stan systemu, od zapytań, które tylko odczytują dane.
- Model zapisu i model odczytu mogą mieć inną strukturę, inne reguły i nawet inną technologię.
- CQRS pomaga szczególnie tam, gdzie odczyt i zapis mają różne obciążenie albo różne cele biznesowe.
- To nie jest obowiązkowo osobna baza danych, ale często kończy się osobnymi modelami lub projekcjami.
- Największym ryzykiem jest złożoność, zwłaszcza gdy zastosuje się ten wzorzec do zbyt prostego systemu.
Czym jest CQRS i dlaczego w ogóle istnieje
CQRS, czyli Command Query Responsibility Segregation, to wzorzec architektoniczny, w którym operacje zapisujące stan systemu rozdziela się od operacji odczytujących dane. Komenda coś zmienia, zapytanie tylko zwraca wynik. Brzmi banalnie, ale w praktyce ten podział bywa bardzo użyteczny, bo pozwala potraktować zapis i odczyt jak dwa różne problemy, a nie jedną, wymuszoną kompromisami całość.
W dobrze zaprojektowanym CQRS komenda nie mówi „zaktualizuj pole X”, tylko wyraża intencję biznesową, na przykład „zarezerwuj pokój” albo „anuluj zamówienie”. Zapytanie działa odwrotnie: ma zwrócić dane w formie wygodnej dla interfejsu, raportu albo API, najczęściej jako DTO, czyli prosty obiekt transferowy bez logiki domenowej.
Źródłem problemu jest to, że aplikacja nie zawsze chce czytać i pisać w ten sam sposób. Formularz zamówienia potrzebuje walidacji, reguł biznesowych i kontroli spójności. Panel analityczny chce szybkich, wygodnych do agregacji danych. Jeden model danych rzadko dobrze obsługuje oba scenariusze naraz.
Ważne rozróżnienie: CQRS nie oznacza automatycznie dwóch baz danych. Często zaczyna się od dwóch modeli w kodzie, a dopiero później dochodzi fizyczny podział storage’u. To właśnie ten etap ludzie często mylą z samą ideą wzorca.
Ten fundament prowadzi wprost do pytania, jak CQRS wygląda w działającej aplikacji.
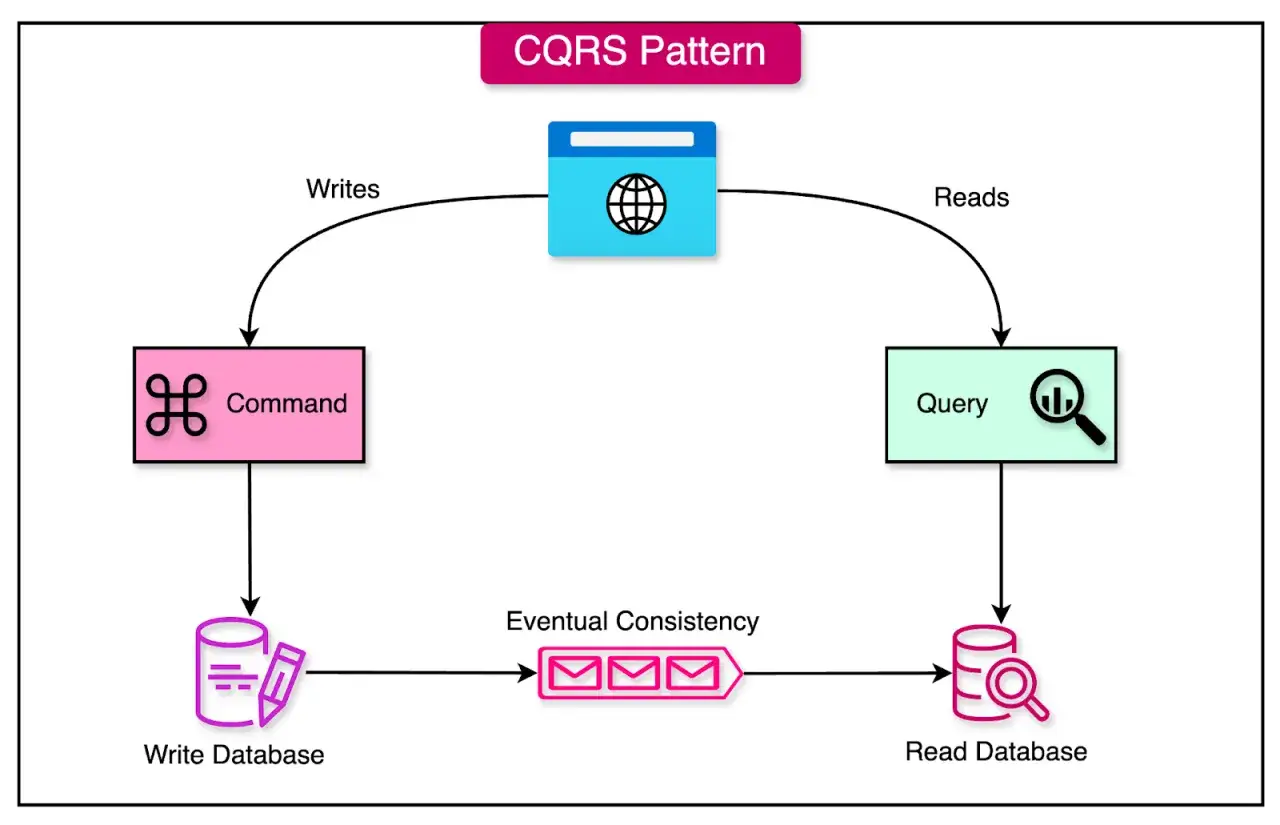
Jak ten wzorzec działa w praktyce
Najprostszy obraz CQRS jest taki: użytkownik wysyła komendę, system ją waliduje i zapisuje zmianę, a osobny model przygotowuje dane do odczytu. Dzięki temu to, co służy do zapisu, nie musi być wygodne dla raportu, a to, co służy do odczytu, nie musi udawać pełnego modelu domeny.
- Użytkownik wykonuje akcję, na przykład „Złóż zamówienie”.
- Komenda trafia do handlera, który sprawdza reguły biznesowe.
- Model zapisu aktualizuje stan, zwykle w ramach jednej spójnej transakcji.
- Jeśli system korzysta z projekcji, czyli gotowego do odczytu widoku danych, read model jest aktualizowany na podstawie zdarzenia lub wyniku zapisu.
- Zapytania czytają dane z modelu odczytu, który jest zoptymalizowany pod konkretny widok.
W e-commerce to dobrze widać. Komenda „Dodaj produkt do koszyka” musi pilnować limitów, dostępności i reguł promocji. Z kolei widok koszyka ma być szybki, czytelny i gotowy do wyświetlenia w aplikacji. Te dwa cele nie są identyczne, więc sztuczne trzymanie ich w jednym modelu często tylko komplikuje projekt.
Tu pojawia się ważny kompromis: read model może być chwilowo nieaktualny. Jeśli zapis i odczyt są rozdzielone, aplikacja może przez moment pokazywać starszy stan danych, czyli działać z ostateczną spójnością. W systemach biznesowych to zwykle akceptowalne, ale tylko wtedy, gdy projekt przewiduje taki scenariusz.
Gdy to już widać, łatwiej odróżnić CQRS od innych podejść, z którymi bywa mylony.
CQRS, CQS i CRUD nie znaczą tego samego
W rozmowach technicznych te skróty często wrzuca się do jednego worka, a to błąd. CQS działa na poziomie metod: metoda albo zwraca dane, albo zmienia stan. CQRS idzie wyżej i organizuje całą aplikację wokół osobnych modeli odczytu i zapisu. CRUD to z kolei bardzo prosty mentalny model pracy na rekordach: create, read, update, delete.
| Podejście | Co robi | Najlepiej pasuje do | Typowy minus |
|---|---|---|---|
| CRUD | Jeden model obsługuje tworzenie, odczyt, aktualizację i usuwanie | Proste systemy i klasyczne formularze | Słabo skaluje się przy różnych potrzebach zapisu i odczytu |
| CQS | Metoda albo zwraca wynik, albo zmienia stan | Projektowanie klas i interfejsów | Nie rozwiązuje architektury całej aplikacji |
| CQRS | Oddziela model zapisu od modelu odczytu | Złożone domeny, duży ruch, różne wymagania biznesowe | Dokłada warstwy, projekcje i koszty utrzymania |
| Event sourcing | Stan odtwarza się z sekwencji zdarzeń | Audyt, historia zmian, systemy event-driven | Jeszcze większa złożoność i większa odpowiedzialność projektowa |
Najważniejsze jest to, że CQRS nie wymaga event sourcingu. Te dwa wzorce często chodzą razem, ale nie są tym samym. Jeśli potrzebujesz tylko oddzielić odczyt od zapisu, możesz zatrzymać się wcześniej i nadal mieć sensowne rozwiązanie.
To prowadzi do najpraktyczniejszej części: kiedy ten podział naprawdę daje wartość, a kiedy tylko wygląda dobrze na diagramie.
Kiedy CQRS rzeczywiście pomaga
Ja widzę sens CQRS wtedy, gdy system ma wyraźnie różne potrzeby po stronie odczytu i zapisu. To nie jest wzorzec „na wszelki wypadek”, tylko narzędzie do konkretnych problemów. Microsoft zwraca uwagę, że szczególnie dobrze działa tam, gdzie aplikacja obsługuje wielu równoległych użytkowników, ma task-based UI albo wymaga osobnego strojenia wydajności odczytu i zapisu.
- Masz dużo odczytów i mniej zapisów - read model można optymalizować niezależnie, bez psucia logiki zapisu.
- Interfejs prowadzi użytkownika przez proces krok po kroku - komendy lepiej oddają intencję niż surowe aktualizacje pól.
- Domena ma skomplikowane reguły biznesowe - zapis potrzebuje pełnej walidacji i kontroli spójności.
- Raporty i widoki są bardziej złożone niż dane źródłowe - read model może być denormalizowany i prostszy do odczytu.
- Występują konflikty przy równoczesnych zmianach - rozdzielenie modelu pomaga ograniczyć tarcia na warstwie zapisu.
W praktyce to najczęściej oznacza: zamówienia, rezerwacje, systemy workflow, aplikacje z rozbudowanym panelem operacyjnym, a także część mikroserwisów, gdzie jedna strona chce pisać ostrożnie, a druga czytać bardzo szybko. W prostym CRUD-owym panelu administracyjnym CQRS zwykle będzie przesadą.
Skoro wiadomo, gdzie wzorzec się broni, trzeba uczciwie powiedzieć, ile kosztuje.
Jakie koszty i ryzyka trzeba zaakceptować
Największa pułapka CQRS polega na tym, że łatwo go uznać za eleganckie rozwiązanie problemu, który jeszcze nie istnieje. W rzeczywistości wzorzec dokłada dodatkowe modele, mechanizmy synchronizacji i więcej miejsc, które trzeba testować. To podnosi próg wejścia dla zespołu i zwiększa koszt każdej zmiany.
- Większa złożoność mentalna - trzeba utrzymywać w głowie dwa modele zamiast jednego.
- Ryzyko niespójności - read model może być chwilowo starszy niż write model.
- Więcej kodu wspierającego - projekcje, handlery, asynchroniczne aktualizacje, obsługa błędów.
- Trudniejsze testowanie - trzeba sprawdzać nie tylko wynik, ale też przepływ aktualizacji między modelami.
- Większe znaczenie obserwowalności - logi i metryki stają się ważniejsze, bo błędy rozchodzą się między warstwami.
Typowy błąd, który widzę najczęściej, to rozbijanie całego systemu na CQRS tylko dlatego, że jedna funkcja jest trudna. Lepiej zacząć od jednego bounded contextu, czyli wydzielonego fragmentu domeny z własnymi regułami, albo nawet od jednego kosztownego zapytania. Jeśli wzorzec faktycznie daje ulgę, można go rozszerzać. Jeśli nie, dobrze, że koszt był ograniczony.
Do tego dochodzi jeszcze kwestia narzędzi. Frameworki ORM, czyli automatyczne mapery obiektów na tabele, nie wyczarują CQRS z samego schematu bazy, bo tutaj potrzebna jest świadoma decyzja o podziale odpowiedzialności. Sam model danych nie wystarczy.
Właśnie dlatego rozsądne wdrożenie jest ważniejsze niż sama nazwa wzorca.
Jak wdrażać CQRS bez niepotrzebnego przeciążenia zespołu
Ja zwykle zaczynam od kodu, nie od infrastruktury. Najpierw wydzielam komendy i zapytania w logice aplikacji, a dopiero później sprawdzam, czy osobny read model albo osobna baza faktycznie coś upraszcza. To pozwala uniknąć sytuacji, w której architektura wyprzedza realne potrzeby produktu.
- Zidentyfikuj operacje zmieniające stan systemu i nazwij je komendami.
- Zostaw jeden, spójny model źródłowy dla zapisu.
- Dla najdroższych lub najczęściej używanych odczytów zbuduj osobne projekcje.
- Jeśli pojawia się duży ruch lub wiele integracji, rozważ asynchroniczne przetwarzanie zdarzeń.
- Monitoruj opóźnienie między zapisem a odczytem oraz liczbę konfliktów biznesowych.
Ważny detal: osobna baza danych nie jest obowiązkiem. Czasem wystarczy osobny model, widok albo dedykowana tabela do odczytu. Fizyczny podział ma sens wtedy, gdy przynosi wymierny zysk w wydajności, skalowaniu lub czytelności odpowiedzialności. Bez tego łatwo stworzyć system bardziej skomplikowany, ale niekoniecznie lepszy.
Jeśli mam sprowadzić temat do jednej praktycznej decyzji, to pytam nie „czy CQRS brzmi nowocześnie”, tylko „czy zapis i odczyt naprawdę przestały być tym samym problemem”. Ta różnica zwykle rozstrzyga wszystko.
Co sprawdzam, zanim uznam CQRS za dobry wybór
Przed wdrożeniem zadaję sobie trzy proste pytania. Po pierwsze: czy odczyt i zapis mają różne wymagania wydajnościowe albo strukturalne? Po drugie: czy domena ma tyle reguł, że jeden model zaczyna się uginać? Po trzecie: czy zespół udźwignie dodatkową warstwę odpowiedzialności, testów i monitoringu?
- Jeśli na dwa z trzech pytań odpowiedź brzmi „tak”, CQRS zaczyna mieć sens.
- Jeśli problemem jest tylko jeden wolny raport, często wystarczy osobny widok albo reporting database, czyli baza raportowa.
- Jeśli system jest prosty, klasyczny CRUD będzie tańszy, szybszy i bezpieczniejszy.
W praktyce najlepsze wdrożenia CQRS nie próbują udowodnić niczego na siłę. Rozwiązują konkretny problem w konkretnym miejscu systemu, a nie zmieniają całej architektury dla samej elegancji. I to jest dla mnie najuczciwszy sposób myślenia o tym wzorcu.
CQRS warto traktować jak narzędzie do trudniejszych fragmentów aplikacji, a nie jako domyślny standard. Gdy zapis i odczyt naprawdę zaczynają żyć własnym życiem, ten podział potrafi porządnie odciążyć kod i zespół. Gdy różnic nie ma, prostszy model zwykle wygrywa szybciej, taniej i bez zbędnej komplikacji.